XPath is designed to allow the navigation of XML documents,with the purpose of selecting individual elements, attributes, or some other part of an XML document for specific processing.
What is XML?
The Extensible Markup Language (XML) is the context in which the XML Path Language, XPath, exists.
XML provides a standard syntax for the markup of data and documents.
XML documents contain one or more elements. If an element contains content,whether other elements or text, then it must have a start tag and an end tag. The text contained between the start tag and the end tag is the element’s content.
<Element> //Start tag
Element content goes here.//Element Content
</Element>//End Tag
An element may have one or more attributes, which will provide additional information
about the element type or its content.
Below is the sample XML:
<?xml version='1.0'?>
<Catalog>
<Book>
<Title>XML Tutorial</Title>
<Author>Selenium Easy</Author>
</Book>
</Catalog>It can also be written as:
<?xml version='1.0'?>
<Catalog>
<Book Title="XML Tutorial" Author="Selenium Easy">
</Book>
</Catalog>XPath can be viewed as a way to navigate round XML documents. Thus XPath has similarities to a set of street directions.
When you need to search for a address, you should know what is your starting point to reach your destination.
In XPath the starting point is called the context node.
Absolute XPath
Absolute XPath starts with the root node or a forward slash (/).
The advantage of using absolute is, it identifies the element very fast.
Disadvantage here is, if any thing goes wrong or some other tag added in between, then this path will no longer works.
Example:
If the Path we defined as html/head/body/table/tbody/tr/th
If there is a tag that has added between body and table as html/head/body/form/table/tbody/tr/th
The first path will not work as 'form' tag added in between
Relative Xpath
A relative xpath is one where the path starts from the node of your choise - it doesn't need to start from the root node.
It starts with Double forward slash(//)
Syntax: //table/tbody/tr/th
Other example :- .//*[@id='username']
The '.' at the start indicates that the processing will start from the current node.
And '*' is used for selecting all the element nodes descending from the current node with @id-attribute-value equal to 'username'.
Advantage of using relative xpath is, you don't need to mention the long xpath, you can start from the middle or in between.
Disadvantage here is, it will take more time in identifying the element as we specify the partial path not (exact path).
If there are multiple elements for the same path, it will select the first element that is identified
XPath Axes :
XPath has a total of 13 different axes, which we will look at in this section. An XPath axis tells the XPath processor which “direction” to head in as it navigates around the hierarchical tree of nodes.
| Xpath axis Name | Description |
|---|---|
| self | Which contains only the context node |
| ancestor | contains the ancestors of the context node, that is, the parent of the context node, its parent, etc., if it has one. |
| ancestor-or-self | contains the context node and its ancestors |
| attribute | contains all the attribute nodes, if any, of the context node |
| child | contains the children of the context node |
| descendant | contains the children of the context node, the children of those children, etc. |
| descendant-or-self | contains the context node and its descendants |
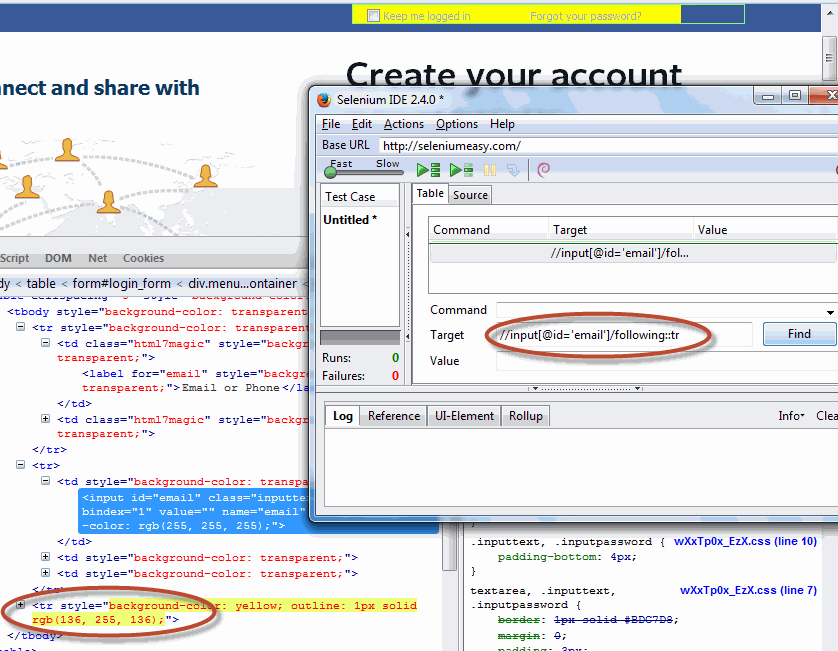
| following | contains all nodes which occur after the context node, in document order |
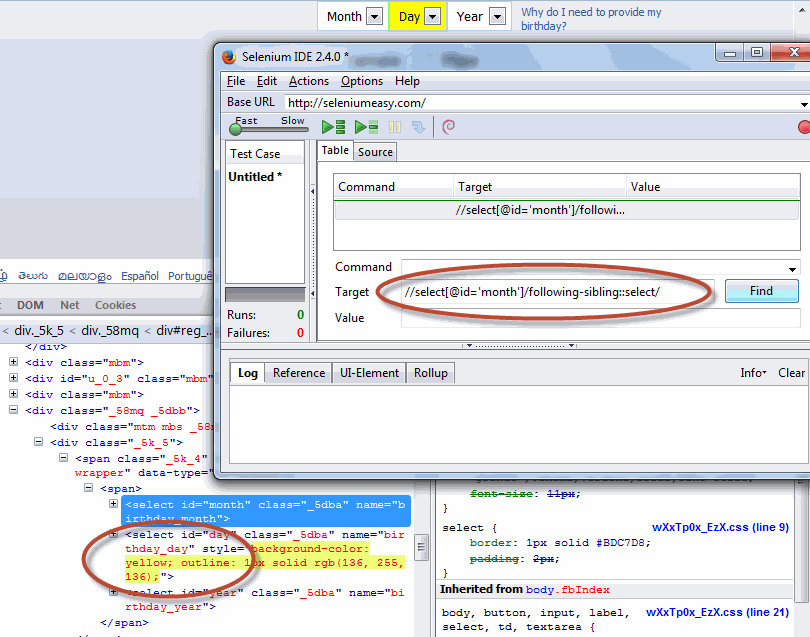
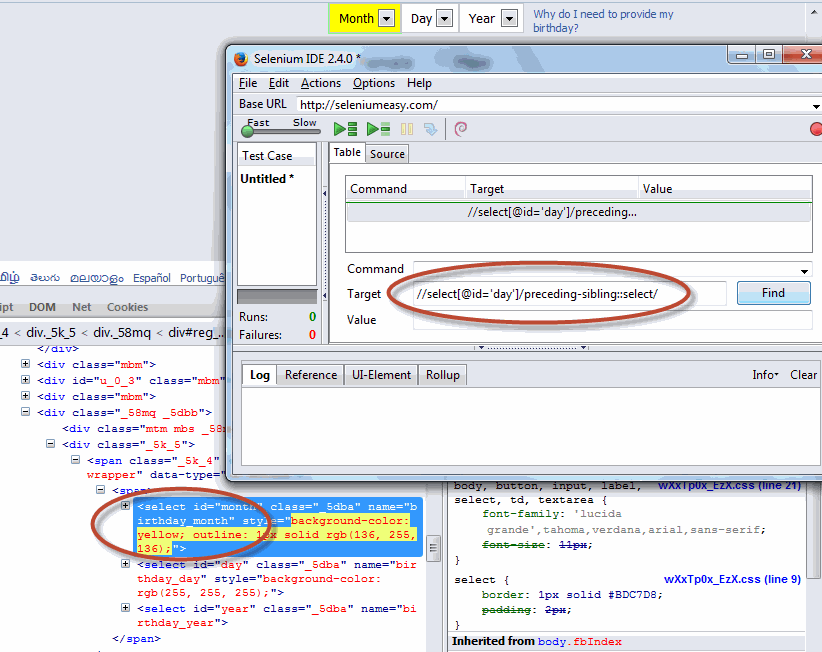
| following-sibling | Selects all siblings after the current node |
| namespace | contains all the namespace nodes, if any, of the context node |
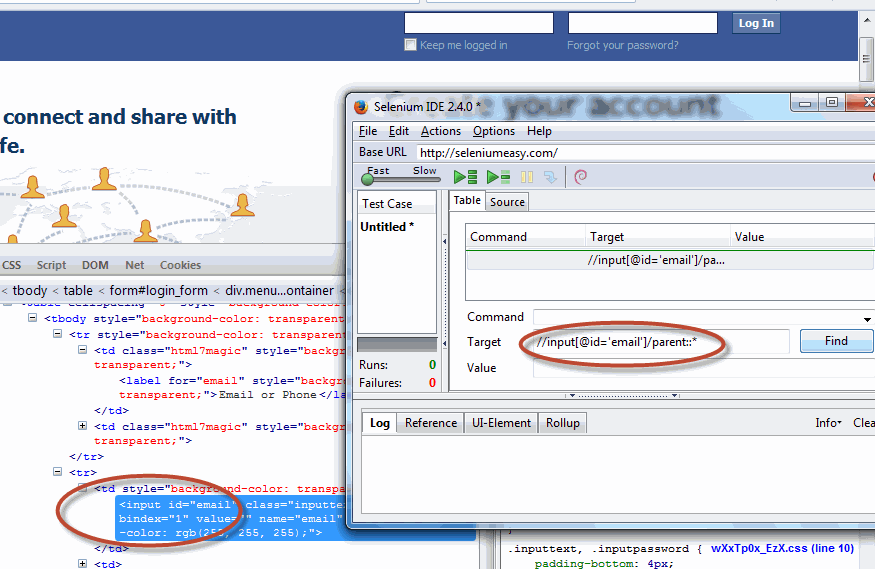
| parent | Contains the parent of the context node if it has one |
| preceding | contains all nodes which occur before the context node, in document order |
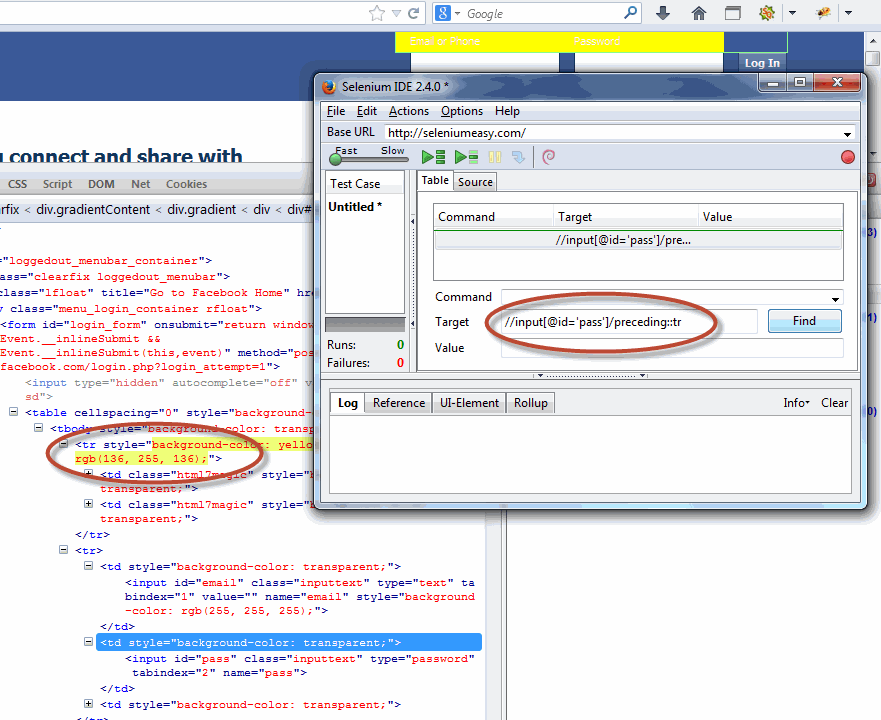
| preceding-sibling | contains the preceding siblings of the context node |
The below are the Axes that are very useful
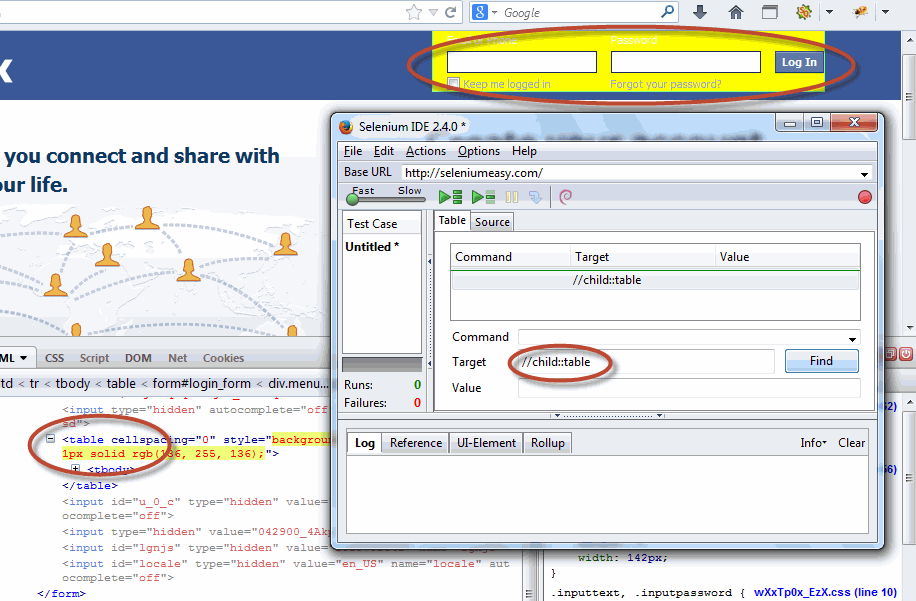
1. Child Axes
The child axis defines the children of the context node.
Child::*
Syntax:
//child::table The first location step selects the child element node of the root node, which represents the element root

- ‹ How to Add Title, Author, Subject and keywords to the Pdf document using iText
- CSS selectors for Selenium with example ›
Comments
Following-Sibling and Preceding-sibling donot work with IE brwsr
Hi,
I am trying to identify the elements using the Following-sibling and Preceding-sibling in the IE10 browser. It gives the result as Element not identified. This works fine in Firefox.
Could you please clarify is if xpath functions works in IE browser too?
Thank you.
Thanks
It was really helpful..
It cleared all my doubts related to XPath creation in Selenium..
Thanks very much again...
Great article
Very nice article , Well explained aspect of xpath.
Nice Explanation
Understood about xpath competely thanks a lot..
ExtJS automation
Mr. Raju,
Thanks forsuch useful tutorial.
I have a question and don't have a clear answer. I try to automeate ExtJS Web Application. In ExtJS such attrubutes as ID, STYLEs are dynamically updeted. So one thing I can do is ro write Xpath locaters by locating to the TEXT of an element. But as I understant it's not the best idea. And another problem - Come elements appear on the page only after clicking on another element. For example, INPUT appears only after clicking on it's DIV element. How do you cope with that?
What should I do to write correct Xpath for my certain situation? When I work with tables it becomes much more complex. And I have to write really big locators.
Thanks for youe answers!
xpath axes
really helpful.
Excellent examples with snapshots
Feedback
Really Helpful!!
Thanks!
unable to identify the Element while passing the Index value
I am passing the index, but it shows that "The Type of Expression must be an array type but it resolved to By" . How to resolve this.
driver.findElement(By.xpath("//div[@class='hd-input-prompt' and contains(text(), '*Nature of Business')]/following::input[@type='text']")[0]);
Add new comment